
 открыть бот
открыть бот


О сетевой аварии в Яндексе
6 февраля пользователи могли заметить частичную недоступность сервисов Яндекса. Проблема возникла из-за каскадного сбоя в работе сетевого оборудования.Основной пик пришёлся на период с 17:03 до 17:50, когда общие потери трафика достигали 40%. Кроме того, в период с 17:03 до 17:13 наблюдалась практически полная потеря IPv6 трафика. Инцидент удалось устранить к 21:30.Как это произошло и какие выводы мы из этого извлекли — ответим на эти вопросы и поделимся нашим опытом.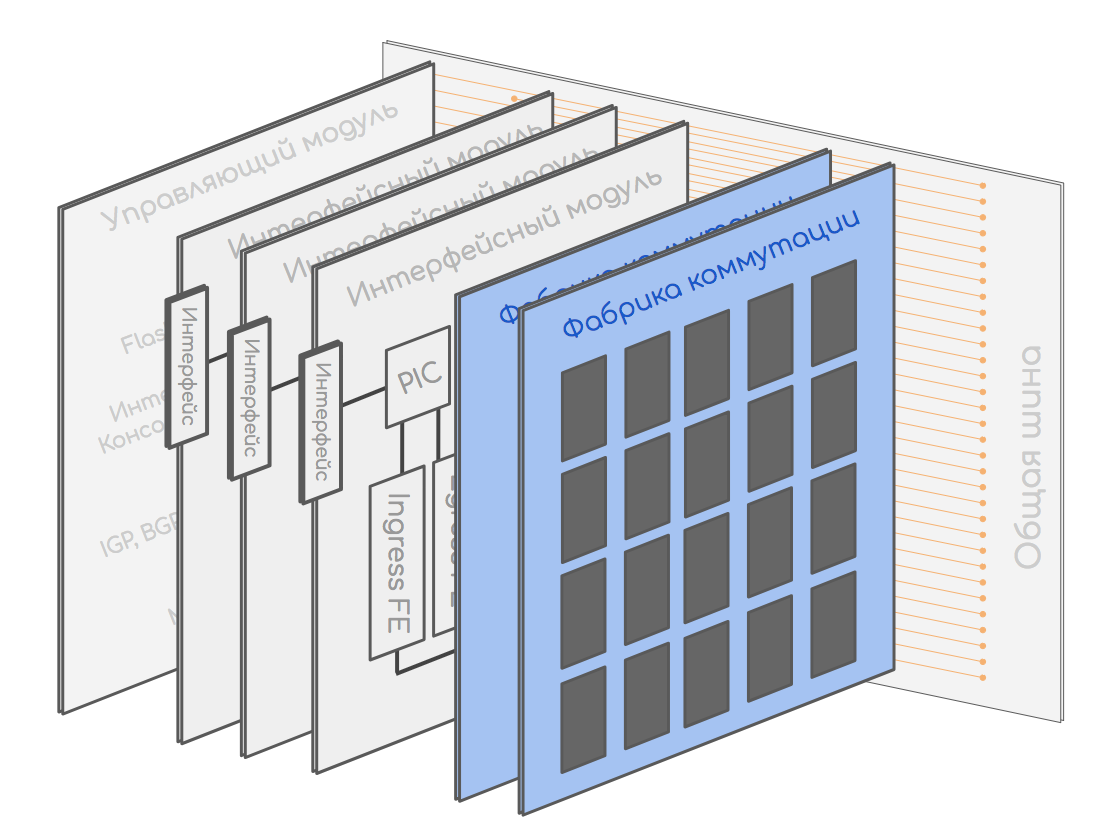 6 февраля в 17:03:30 на одном из наших граничных маршрутизаторов вышла из строя управляющая плата или её «ответная» часть, на которой расположена фабрика коммутации и вся машинерия для контроля состояния аппаратных компонентов. Мы до сих пор не знаем точной причины, потому что оживить коробку так и не удалось. По итогу маршрутизатор был потерян полностью.Эту проблему могла бы предотвратить резервная управляющая плата, но она отказала ещё 22 января, а работы по её замене были запланированы, но не завершены. Вообще, отключение резервных плат не влияет на прохождение трафика, поэтому её заменили не сразу. Отчасти это связано с тем, что место расположения маршрутизатора обслуживается не нашей службой Smart Hands, а сторонними выездными инженерами. Кроме того, отказ одного маршрутизатора не должен был стать критичной проблемой, потому что все пиринги зарезервированы маршрутизаторами на других точках присутствия. В прошлом такие аварии не приводили к заметным для пользователей инцидентам, но не в этот раз.
6 февраля в 17:03:30 на одном из наших граничных маршрутизаторов вышла из строя управляющая плата или её «ответная» часть, на которой расположена фабрика коммутации и вся машинерия для контроля состояния аппаратных компонентов. Мы до сих пор не знаем точной причины, потому что оживить коробку так и не удалось. По итогу маршрутизатор был потерян полностью.Эту проблему могла бы предотвратить резервная управляющая плата, но она отказала ещё 22 января, а работы по её замене были запланированы, но не завершены. Вообще, отключение резервных плат не влияет на прохождение трафика, поэтому её заменили не сразу. Отчасти это связано с тем, что место расположения маршрутизатора обслуживается не нашей службой Smart Hands, а сторонними выездными инженерами. Кроме того, отказ одного маршрутизатора не должен был стать критичной проблемой, потому что все пиринги зарезервированы маршрутизаторами на других точках присутствия. В прошлом такие аварии не приводили к заметным для пользователей инцидентам, но не в этот раз.
Мы опубликовали этот разбор, потому что считаем важным объяснять причины серьёзных аварий. Полезно не только рассказывать о достижениях, но и признавать слабые места. В конечном счёте это поможет нам извлечь урок и защитить пользователей от подобных аварий в будущем, а также помочь другим компаниям в диагностике сложных сетевых сбоев.
Ход инцидента
Граничные маршрутизаторы — это то место, где проходит граница между разными сетями связи. От их работы зависит связность между Яндексом и сетями, которые обеспечивают подключение конечных пользователей.Мы столкнулись с четырьмя проблемами, три из которых связаны друг с другом, а четвёртая, похоже, просто произошла одновременно с ними:- аппаратный сбой граничного маршрутизатора;
- последовавший за этим сбой подсистемы лукапа и аварийные перезагрузки линейных карт на трёх других георазнесённых граничных маршрутизаторах;
- сбой ПО на пяти маршрутизаторах внутри дата-центров Яндекса;
- нестабильность контрольного протокола BFD из-за флапа MAC-адресов внутри CLOS-фабрики на М9.
Проблема №1
Началом инцидента мы считаем аппаратный отказ на одном из граничных маршрутизаторов, который привёл к его полному отключению.Немного теории. Современный маршрутизатор состоит из набора различных плат:- управляющих,
- линейных, на которых есть интерфейсы,
- фабрик коммутации, которые соединяют всё воедино.
6 февраля в 17:03:30 на одном из наших граничных маршрутизаторов вышла из строя управляющая плата или её «ответная» часть, на которой расположена фабрика коммутации и вся машинерия для контроля состояния аппаратных компонентов. Мы до сих пор не знаем точной причины, потому что оживить коробку так и не удалось. По итогу маршрутизатор был потерян полностью.Эту проблему могла бы предотвратить резервная управляющая плата, но она отказала ещё 22 января, а работы по её замене были запланированы, но не завершены. Вообще, отключение резервных плат не влияет на прохождение трафика, поэтому её заменили не сразу. Отчасти это связано с тем, что место расположения маршрутизатора обслуживается не нашей службой Smart Hands, а сторонними выездными инженерами. Кроме того, отказ одного маршрутизатора не должен был стать критичной проблемой, потому что все пиринги зарезервированы маршрутизаторами на других точках присутствия. В прошлом такие аварии не приводили к заметным для пользователей инцидентам, но не в этот раз.Проблема №2
Обычно распределение нагрузки между оставшимися маршрутизаторами обрабатывается штатно: сессии и соседства контрольных протоколов (BGP, IS-IS) должны были уйти по таймауту, а трафик — перейти на резервный маршрут. Пользователи не должны такого замечать, но кое-что пошло не так — ниже разберёмся, что именно.Полная потеря связности с отказавшим маршрутизатором привела к падению протокольных соседств IS-IS — это заняло около секунды. А вот отзыв BGP-маршрутов занял несколько больше: связность внутри нашей автономной системы организована с помощью рефлекторов, поэтому системе потребовалось некоторое время на обработку событий падения BGP-сессий между рефлекторами и отказавшим маршрутизатором, а также на отзыв маршрутов с других бордеров.Таким образом, в течение нескольких секунд все оставшиеся в живых пограничные маршрутизаторы оказались в ситуации, когда BGP-маршрут ещё присутствовал, а вот IS-IS маршрут, необходимый для его корректного рекурсивного разрешения, — уже нет.Рекурсивное разрешение маршрута в BGP — это процесс вычисления актуального выходного интерфейса и выходной инкапсуляции для BGP-маршрута. Он производится исходя из значений протокольного Next-hop маршрута и актуального состояния таблиц маршрутизации. Происходит однократно либо в момент создания маршрута, либо значимого изменения его атрибутов. Необходим для программирования корректной записи в FIB.Lookup (или лукап) — это процесс поиска подходящей записи в таблицах маршрутизации, коммутации и других (например, FIB, LFIB, ARP Adjacencies, IPv6 ND Table) на основании значения адреса назначения IP-пакета. В современных аппаратных маршрутизаторах это происходит индивидуально для каждого пакета: то есть за короткое время — скажем, секунду — на высоконагруженном маршрутизаторе этот процесс повторяется огромное количество раз.В таких условиях BGP-маршрут в нашей конфигурации рекурсивно разрешился не самым очевидным образом. Из-за отсутствия IS-IS маршрута разрешение происходило через маршрут по умолчанию, который, в свою очередь, был статическим. Он указывал в таблицу маршрутизации, с которой и начался процесс нашего рекурсивного лукапа.Круг замкнулся: в FIB маршрутизаторов сформировалась замкнутая цепочка логических next-hop, приводившая к тому, что процесс лукапа над пакетом не завершался за разумное время.С точки зрения способности пограничных маршрутизаторов отправлять трафик у этой ситуации были следующие последствия:- у пакетов, которым выпадал этот маршрут, не было ни единого шанса «вынырнуть» из маршрутизатора;
- что ещё хуже — все имеющиеся аппаратные ресурсы линейных карт были заняты бесконечным лукапом крайне небольшого числа пакетов.
Проблема №3
Вскоре после того, как пограничные маршрутизаторы оправились от предыдущей проблемы и её прямых последствий, стала заметна частичная потеря трафика на маршрутизаторах на границе наших дата-центровых фабрик.У этой проблемы была несколько иная природа: дело в том, что неделей ранее мы начали плановое обновление ПО на этих маршрутизаторах и к 6 февраля у нас было пять обновлённых устройств. В итоге мы выяснили, что потери трафика локализуются как раз на них.Нестабильность в сети кратно увеличила количество изменяющейся маршрутной информации. Из-за этого появились маршруты, застрявшие в очереди от процесса, который реализовывал протоколы маршрутизации к ядру, которое, в свою очередь, должно было записать итоговые изменения в программный FIB, а затем и в аппаратный.Мы продолжаем выяснять детали, но можем утверждать, что с высокой долей вероятности это ещё один баг в ПО одного из наших устройств. После даунгрейда проблема была решена.Проблема №4
Но и это был ещё не конец инцидента: коллеги из Yandex Cloud сообщили о потерях части трафика сервиса объектного хранилища через одну из магистральных площадок. Сначала мы исследовали проблему на граничных маршрутизаторах, подозревая возврат первой проблемы с линейными картами, но эта гипотеза не подтвердилась.Потом мы посмотрели, что происходит на транзитных устройствах, и выяснили, что на подключении между магистралью и бордером циклически переустанавливается контрольный протокол BFD и это приводит к постоянному перестроению сети. Искать причину мы сразу стали на промежуточных коммутаторах CLOS-фабрики, потому что ранее уже наблюдали похожую проблему с пиринговыми партнёрами в той же локации.Наша догадка подтвердилась: мы увидели MAC-флаппинг, только источником теперь был DHCP-пакет, прилетевший со стороны магистрали на М9. В обычной ситуации такого быть не должно — у нас нет DHCP серверов в локации M9.Мы уже знали, как исправить эту проблему: выключить DHCP-протокол на коммутаторах CLOS-фабрики на точке присутствия М9, которую мы используем для увеличения количества пиринговых портов. В прошлом мы уже поставили заплатку в виде аксесс-листа на все внешние пиринговые порты, запрещающего DHCP-пакеты на вход в фабрику. Но мы не ожидали, что такие пакеты могут прийти изнутри, из-за чего эта проблема и возникла.Чтобы избежать повторения данной проблемы, мы выключили функциональность DHCP на коммутаторах пиринговой фабрики. Защищаться на портах в сторону нашей сети мы не видим смысла, потому что не хотим блокировать пользовательский трафик.Таким образом, этот инцидент не связан напрямую с тремя вышеописанными, но мог каким-то косвенным образом быть вызван ими. В любом случае в обновлённой конфигурации он больше не появится.Итог
В ходе инцидента мы столкнулись с рядом нетривиальных проблем, которые мы смогли быстро детектировать и локализовать.Мы приняли ряд мер, которые не позволят подобному инциденту произойти вновь. Заменили отказавший маршрутизатор на полностью рабочий. Научились воспроизводить аварийную ситуацию в нашей лаборатории. В будущем она будет исправлена на уровне операционной системы производителя сетевого оборудования.Мы уже достаточно давно думаем над диверсификацией граничных маршрутизаторов, чтобы баги, специфичные для конкретной конфигурации, не приводили к каскадной аварии. Но, к сожалению, используемая нами функциональность медленно разрабатывается другими производителями. Стратегически мы планируем:- внедрить второго вендора на этом участке сети;
- проработать вопрос упрощения сетевого дизайна;
- улучшить систему квалификации вендорского ПО.
Мы опубликовали этот разбор, потому что считаем важным объяснять причины серьёзных аварий. Полезно не только рассказывать о достижениях, но и признавать слабые места. В конечном счёте это поможет нам извлечь урок и защитить пользователей от подобных аварий в будущем, а также помочь другим компаниям в диагностике сложных сетевых сбоев.